

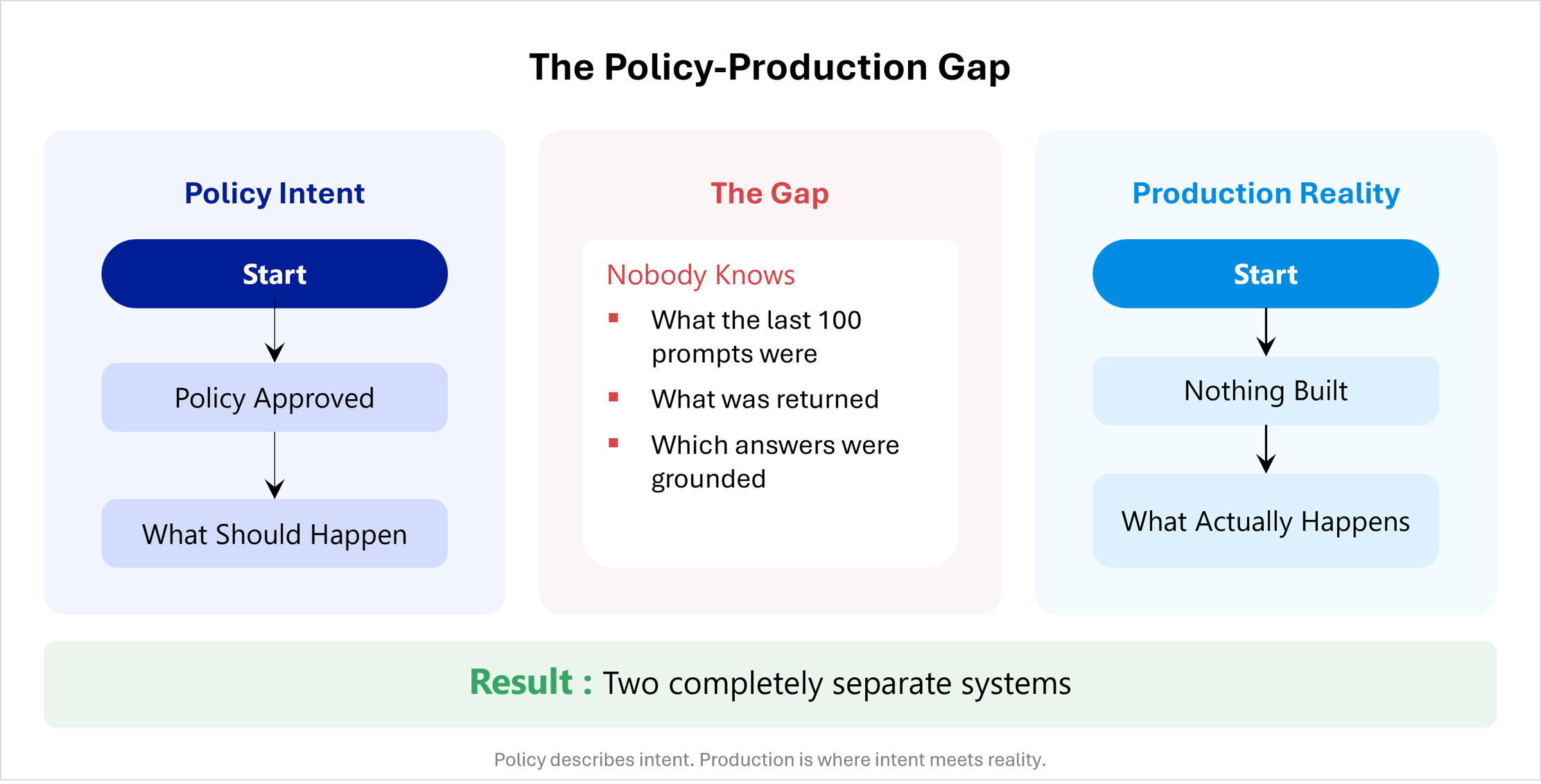
Most pharma AI policies I've read are well-written. Thoughtful. Forty pages on fairness, transparency, human oversight, and data minimization. Approved by a steering committee. Signed by legal.
And completely disconnected from what's actually happening in production.
Here's the test I now run with clients. I ask one question: "Can you show me the last 100 prompts your Enterprise Knowledge Assistant, what it returned, and which of those answers came from your approved content versus the model making something up?"
Almost nobody can answer.
That's the gap. The policy describes intent. Production is where intent meets reality. Most organizations have confused the first for the second.
Why this Gap Exists
Policies get written by governance, legal, and risk. Runtime controls get built by engineering and MLOps. These two groups don't share a roadmap, a budget, or a vocabulary. The policy says, "outputs must be monitored for accuracy." Engineering hears a vague aspiration. Nothing gets built. The policy becomes the artifact instead of the practice.
Then something goes wrong a hallucinated dosing claim in an HCP email, a rep prompt that surfaces another customer's data, a model drifting into off-label territory, and everyone discovers the policy was never actually in the loop.
What Runtime Governance Actually Means
If you want governance that holds up in production, here's what has to exist:
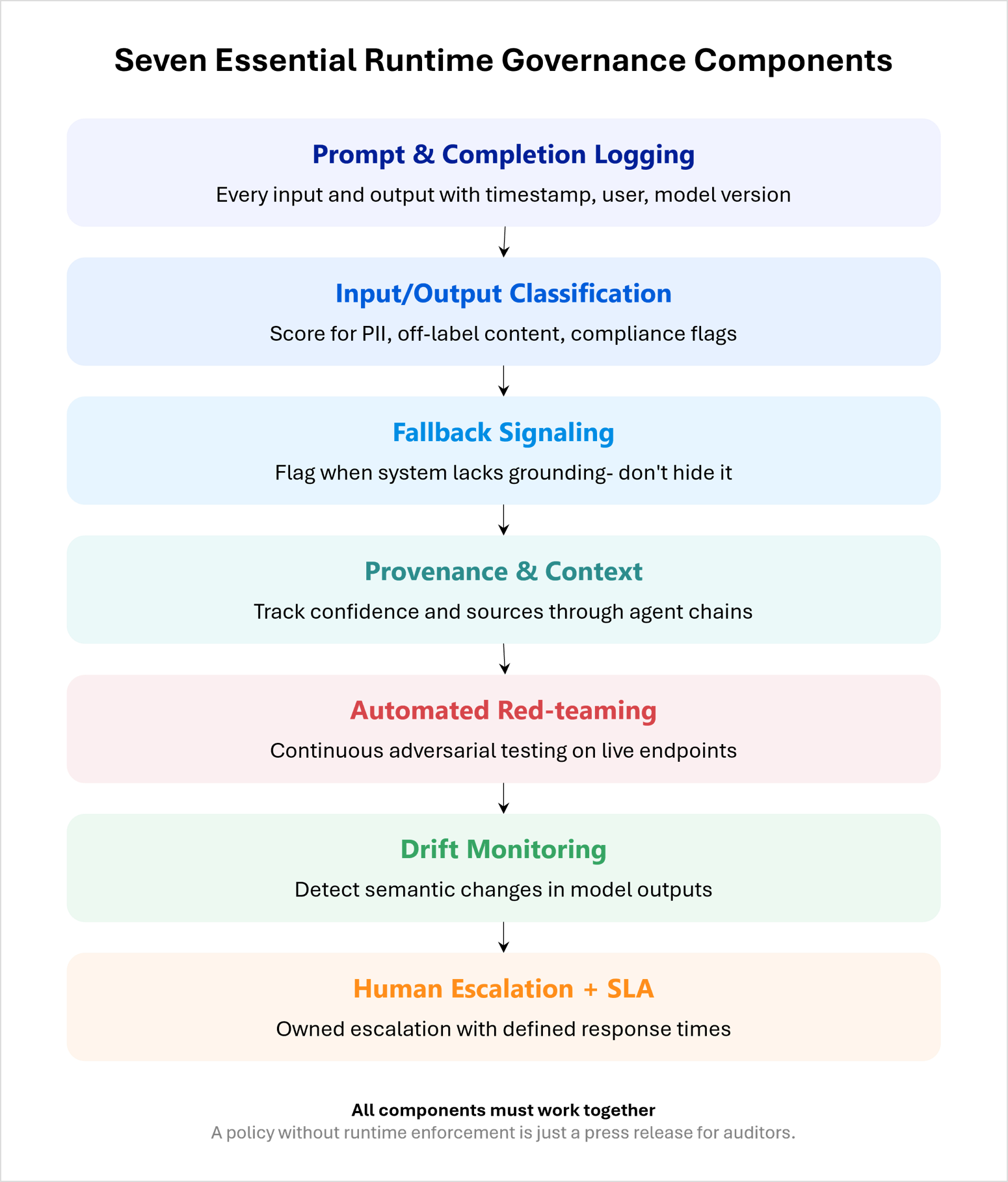
- Prompt and completion logging. Every input and output, captured with user, timestamp, model version, system prompt, and retrieved context. Not sampled. All of it. Without this you have no audit trail, no failure analysis, and no training data for your own controls.
- Input and output classification at inference time. A second layer that scores every prompt and every response for PII, off-label content, claims that need medical review, competitor mentions, regulatory red flags. Block, flag, or route based on the score. This happens before the user sees the output, not after.
- Explicit fallback signaling. When your system can't find a good answer in your approved content and falls back to the base model's general knowledge, that's not a graceful degradation. It's a change in where the answer is coming from. It needs to be flagged logged, surfaced in the UI if it reaches a user, counted in metrics. The same principle applies when retrieval is weak: if your top match scores are below threshold, don't paper over it with a generic answer. Surface it. Confident output with no grounding is the worst possible failure mode it looks right and it isn't.
- Provenance across agents. When agents call other agents research agent hands to drafting agent hands to compliance-checking agent trust and context have to travel with the request. Confidence scores, retrieval quality, fallback flags, source attribution. Whether you implement this as checksums, signed payloads, or provenance tokens is a design choice. The principle is non-negotiable: no agent in the chain should lose track of where an assertion came from or how confident the previous step was.
- Automated red-teaming on production traffic. Adversarial prompts running continuously against your live endpoints. You find the failure modes before a regulator or a journalist does. This is not a one-time pen test. It's a daily background process.
- Drift monitoring on outputs. Not just statistical drift on inputs semantic drift on what the model is producing. Is it phrasing things differently than it did at validation? Is the tone shifting? Are certain topics quietly appearing more often?
- Human escalation with SLAs. When the classifier flags something, where does it go, who owns it, and how fast does it get resolved? "Human in the loop" without an SLA is decoration.
- Kill switches. Can you disable a model in production in under five minutes? Most clients I work with cannot.
Governance is a Running Cost, Not a Launch Event
This is the part most client’s underestimate.
- AG systems get worse over time, not better, unless someone is actively maintaining them. Corpora rot. Old SOPs, deprecated brand guidelines, superseded medical content the system happily retrieves them because nobody told it they're stale. Set expiry dates on content. Flag documents that haven't been reviewed in months. Make removal as easy as addition.
- Context bloat degrades the model. Bigger context windows are not free. More retrieved chunks mean more competing instructions, more conflicting facts, more chances for the model to anchor on the wrong thing. Retrieving fewer, higher-quality chunks often beats retrieving more. What worked with 5,000 documents is often wrong at 50,000.
- Embedding models improve. Chunking strategies evolve. New document types arrive that the original schema didn't anticipate. Plan for periodic re-embedding not as a rebuild, as scheduled maintenance.
- Eval sets need maintenance too. The held-out question set you used to validate retrieval at launch has to evolve. Questions users actually ask in year two may not be in your eval set at all. Treat it like a regression suite, not a one-time deliverable.
- And somebody has to own all of this. Not "the AI team" a named person, with a maintenance roadmap, an eval cadence, and authority to retire content. Without that, the system has no immune system. Degradation is just a matter of time.
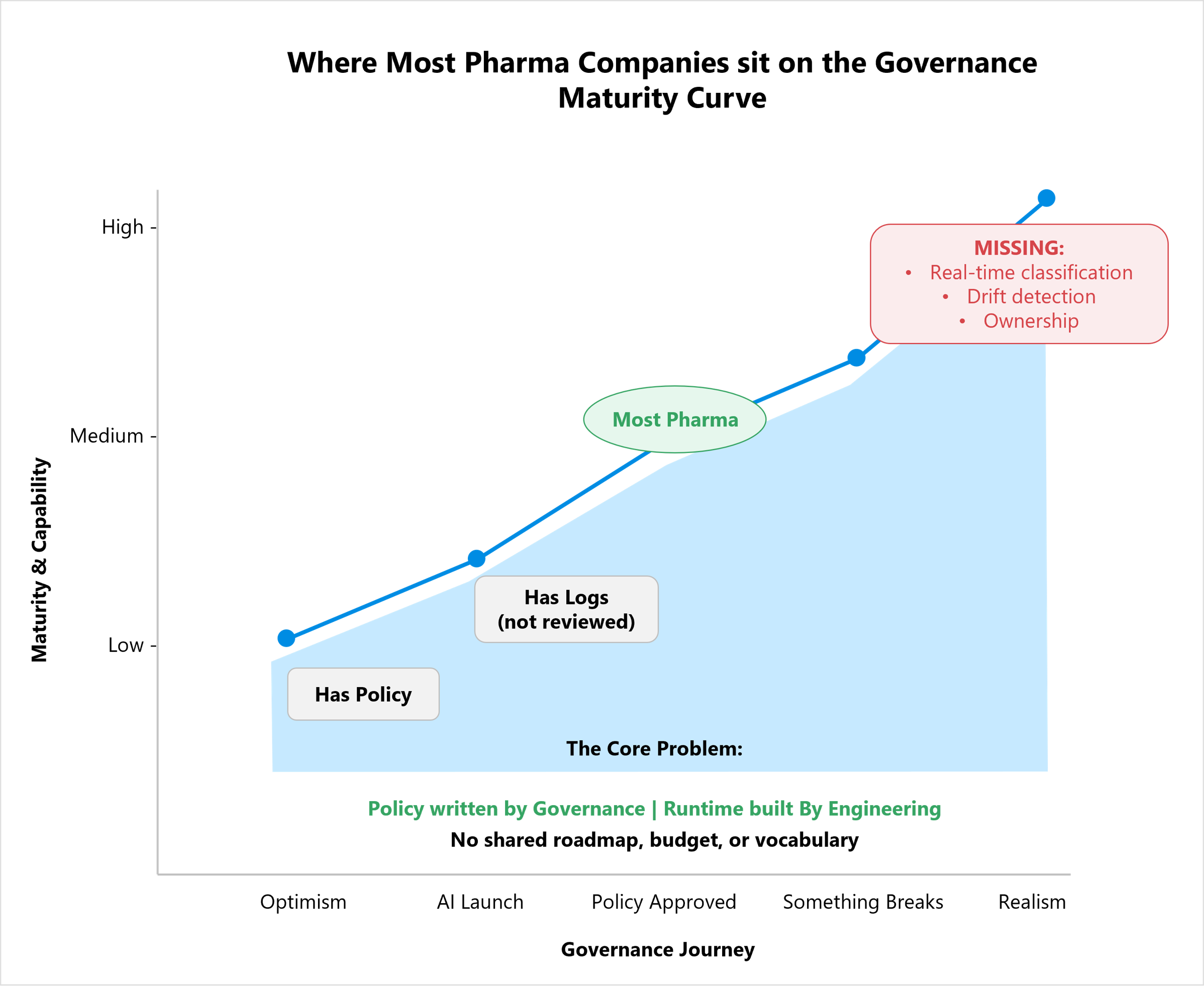
The Pattern I Keep Seeing
Most pharma companies I work with are in roughly the same place.
They have a policy. They have logs sitting somewhere, though nobody looks at them often. They have a review process for new AI use cases. They don't have continuous monitoring. They don't know if quality has slipped since launch. And if you ask who owns the long-term maintenance of the system, the answer is usually a few seconds of silence.
That's not a failure. That's just where the industry is today. The work done so far is real it just doesn't go as far as production needs it to. The first honest step is to say that out loud.
The Reframe
AI systems in production aren't software you ship. They're instruments you tune. The governance question isn't "did we launch it responsibly." It's "are we still tuning it six months in, and who's accountable when we stop."
A policy without runtime enforcement isn't governance. It's a press release you can show to auditors.
If your CISO can't show you yesterday's prompt log and your AI lead can't tell you when the corpus was last cleaned you don't have AI governance. You have AI optimism.
Where does your organization actually sit on this? And more importantly who owns the gap?
Read More Articles
Connect with us


Capabilities
©2026 ProcDNA Inc. | All Rights Reserved